
HRMs are a Big Deal (but not for the reasons you've been told!)
Hierarchical Reasoning Models - The mighty 27M param model that bested multi billion param models from OpenAI & Anthropic underscores the need to model intelligence as a complex system.

The HRM should push AI research towards systems biology and complex adaptive systems in the quest for efficient intelligence.
Let’s begin with the conclusion, so as you read on you can see where we are headed. I conclude that the recently released HRM model exhibits more complexity and inductive bias than many writers stress. It should point AI research more towards complex adaptive systems, and architectures more like The Society of Mind as conceived by Marvin Minsky, where we understand the brain and the mind as a massively parallel society with thousands if not millions of continuously processing, highly interconnected, and cooperating sub agencies working together.

This also parallels the mind-opening research by Michael Levin at Tufts University in systems and synthetic biology showing that intelligence is not restricted to brains, or neural circuits, or even neurons, but exist at all levels of living organisms. Levin and his team’s marvelous experiments show that intelligence extends from organelles to cells to tissue and organs, and even exists in the basic chemical substrates of life. The quest to understand higher order intelligence should therefore be seen as the quest to understand complex systems where higher order agents and lower level agents coexist at many levels, and where agents at all levels have true choice and agency in how they solve problems.
The HRM is a toy system, built to explore new reasoning modes on fairly controlled problems. On its own it is nowhere near as complex as what Minsky posited for the brain, nor what Levin studies in the lab. But the HRM does hide more complexity and levels of interactions, and more levels of “inductive bias” than many reports acknowledge. The coordination of parts, and multiple levels of design, each contribute to its remarkable efficiency. In a small way it mirrors the elaborate but ultimately brutally efficient designs we see in biology.
HRMs are currently much too specialized to dethrone the Large Language Models that we use every day, but they do point to a need to orient AI research towards understanding systems with multiple levels of hierarchy and complex adaptive and recurrent dynamics. The type of dynamics we know brains and other biological systems possess. HRMs may prove to be the most important small model of the year, and help inspire more research towards more energy efficient AI.
Why is this tiny model capturing people’s imaginations?
Ok, if you are like me, you missed the stock market trade of a lifetime this past January.
DeepSeek R1 came out on January 20th, 2025 and just seven days later on January 27th crashed the market and Nvidia stock, as the media began to speculate how a radically more efficient model from China, one that could match OpenAI’s top model on performance, might affect the GPU capital spending boom that undergirds Nvidia’s valuation and the broader AI trade. There were also plenty of stories about the urgency of keeping pace in the AI race with the PRC. If you had loaded up on Nvidia shorts when you got R1 the week before, you would likely be retired today. I myself tested the model for that full week, but it never even occurred to me to open my brokerage account.
So here we are, just a little over two weeks since a mighty model known as the HRM has burst onto the scene. This model of a mere 27M parameters (from the small island nation of Singapore) has defeated many billion parameter models from the leading labs on the “ARC AGI challenge”, a benchmark created by François Chollet and widely regarded as one of the most serious tests of Artificial General Intelligence. A tiny model like the HRM achieving results like this is indeed headline grabbing, and certainly bodes well for research into smaller and more energy efficient models. You would be forgiven for asking yourself, is now the time to short Nvidia?
Perhaps, and perhaps not. This blog is certainly not the place to look for anything resembling financial advance. But there is a deeper story behind HRMs that I think deserves telling.
The Conventional Story of the HRM
It seems funny to talk about the “conventional story” of HRMs doesn’t it? After all it is a model that just appeared a couple weeks ago! I realize to some of you this will seem like a pretty esoteric and perhaps alien topic. Please bear with me though, there should be insights for all, regardless of how closely you follow AI research.
If like me your feeds are flooded with AI material, you have likely already been bombarded with multiple breathless write-ups and videos going into the HRM paper and architecture. Many proclaim its exciting an revolutionary power. The paper itself is an excellent read, and many of these summaries are in fact quite helpful. I recommend starting with the paper to get a more detailed idea of how the model is put together.
A tiny model like the HRM achieving results like this is indeed headline grabbing, and certainly bodes well for research into smaller and more energy efficient models. You would be forgiven for asking yourself, is now the time to short Nvidia?
I won’t repeat the full detail from the paper, but the basic story is straightforward: HRMs have two modules, both of which are transformers. One is called the “low-level module” and the other is called the “high-level module.” These two modules are wired together to operate at two different speeds. The low-level module runs more rapidly than the high-level module, which acts more like a supervisor, receiving occasional updates from the low-level module and then computing its own updates which are fed back to the low-level module to guide it. The low-level module again runs for multiple more steps before sending its next update to the high-level module. The whole cycle repeats several times in training, and also at inference time, when the model is used to make a prediction.
The authors explicitly claim inspiration from the brain where slower theta waves operate at 4-8Hz and faster gamma waves operate at 30-100 Hz, analogous to the slower high-level module and the faster low-level module in the HRM. The following diagram from the paper indicates this inspiration and the role of the two modules.
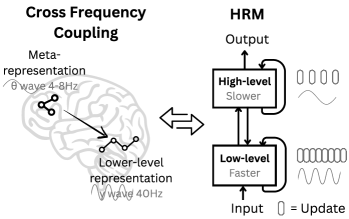
This picture however, and even the full paper, stresses only the two “levels” in the hierarchy of the HRM, and in obscures important elements which may be essential to its performance. Studies are as yet inconclusive, but we are likely to see more research probing the structure and results of the HRM in the weeks and months ahead.
It must be reiterated however that the HRM is in no way a general purpose model, nor in any way a replacement for today’s LLMs. Beyond the ARC AGI challenge, it was trained on two other tasks: finding paths in mazes, and solving Sudoku puzzles. These tasks, like the ARC challenge are known to be particularly difficult for LLMs, which lack recursion and are limited by depth for solving tasks with deep structure and dependencies. The HRM performed very impressively on these tasks, besting the much larger o3-mini-high and Claude 3.7 8K models. The following table from the original paper summarizes the HRMs performance gains across these tasks:
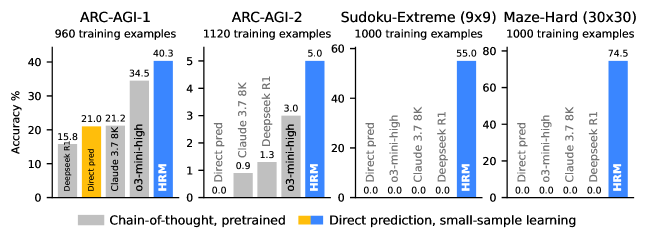
What is not shown here, and must be emphasized is that HRMs are not natural language input / output engines like GPT models, at least as far as they were trained in the paper. In the present incarnation, they certainly cannot take arbitrary prompts from users and return realistic natural language responses, nor generate images, nor do tool calling, nor write code, etc. Simply stated they are much more modest than the foundation models in wide use today. So HRMs are not truly a 27M parameter model about to “dethrone” today’s large foundation models. What they do do, and do impressively, is solve certain kinds of tasks that have proven very challenging for even the largest LLMs. Tasks which large LLMs have made progress on only by spending more and more GPU power on, and which still remain elusive.
More research into what tasks HRMs perform well, and how general the architecture can become is crucial. The headlines the HRM is grabbing are well deserved, but a deeper look reveals more important lessons of the HRM for AI research generally.
A more complex picture of the HRM
A deeper look at the HRM reveals it is not simply a story of two modules, one slow and one fast, working together to find the answer. A recent report from Ndea, the company founded by the creator of the ARC-AGI challenge shows that different parts of the HRM model may contribute to its performance on ARC in different ways. If you have time, the video produced by Ndea “The Surprising Performance Drivers of HRM” is well worth the watch time:
Ndea calls out 5 main factors that make the HRM tick, namely:
Iterative refinement: the model produces an answer via multiple recurrent passes not a single forward pass.
Hierarchical structure: lower and higher frequency forward passes through the high-level (slow) module and the low-level (fast) modules respectively
A learned ‘halt’ signal: leveraging Q-learning a technique in reinforcement learning, this outer “control loop” of the HRM determines how many times the overall cycle of low and high level modules inferencing takes place. This outer loop control loop which in essence determines “how long” the HRM “thinks” is under discussed in many write ups.
Data Augmentation: the HRM training pipeline makes multiple permutations of the training data supplied in the ARC challenge to try to improve learning and performance.
Task Embeddings: In a fairly non-conventional approach for ARC challenge entries, the HRM uses an embedding of the ARC-AGI task rather than present the ARC puzzle directly to the model. The embedding used is a a hash invented by the paper authors and includes a hash of the input puzzle as well as the code of the data augmentations applied to the puzzle.
The Ndea researchers performed ablation studies (a fancy way of saying they tried “not doing” each of the elements in the paper that make up the HRM one by one) to see how much each factor contributed to the performance of the HRM on the ARC-1 challenge. The results are curious, and reveal fresh insights. They do not reflect exactly the narrative most often promulgated around the HRM. Specifically the Ndea researchers found:
Iterative refinement was extremely important to HRM performance, but hierarchy (the two level design) was much less important (though definitely non-zero) to ARC task performance. They found that a single outer refinement loop (rather than a fast level and a slow level alternating) could capture almost as much performance as the two-level HRM in the paper.
The data augmentations performed by the HRM authors were critical to performance, but far fewer were needed than the authors used, and the augmentations were more important at training time than at test time.
The input embedding strategy appeared to play a quite significant role in HRM performance (although the Ndea authors admit more study as needed as this was based not on controlled ablations, but on discussions with the paper authors describing earlier experiments). The input embedding is in some ways the least discussed part of the HRM. In essence it is another “layer of processing” before the two interacting modules. An analogy is the role of convolutions in CNN architectures which are opinionated “feature extractors” from an input image into a form that deeper networks can then train on. The extra structure (and added inductive bias) provided by such a layer is a key design choice for future research to examine. The fact that it may be a critical one in AGI performance underscores that the HRM is a more complex system than is typically realized.
The outer control loop which learns the “halt” signal (the “how long to think” signal) did play a meaningful role in performance, but mostly because more outer-loop iteration was the large driver of performance. In principle the “Q-learned halt” can prevent the loop running longer than needed, and may mimic similar control loops in brains and other biological systems, but the Ndea researchers were able to achieve similar raw performance simply by fixing the number of refinement loops at a sufficiently high number.
For more details please consult the Ndea / ARC report on the HRM here.
Where do these results point?
I certainly encourage you to read the original paper, as well as the Ndea report to draw your own conclusions. I’d love to hear from readers who reach different conclusions from mine! In my view, the importance of the task embeddings to performance, as well as the modest role of the hierarchical layers, and the critical role of recursive refinement at the outer loop, points to a more complex picture than one initially gets from the paper.
The real lesson, I believe, is that more complex adaptive architectures need to be studied. The remarkable performance of HRM on ARC will no doubt stimulate extensive small model research. Particularly important will be to examine a significantly expanded range of tasks, and models that involve HRM style iteration (avoiding the common pitfalls of RNNs like vanishing gradients), and non-deterministic cooperation among elements like input transformation, when to halt reasoning, or learned models for when to employ or trigger alternative reasoning modules or networks. The exact configuration and interplay of cooperating elements (“agencies” in the “society” to use Minsky’s terminology) likely will vary by task and by situation. Probably learned reconfigurations and the learned ability to recruit new agencies at test time to confront novelty will be important.
Recall that the Ndea researchers only did ablations against the ARC AGI benchmark evaluation data, not against other tasks from the paper like maze navigation or puzzles like Sudoku. So their conclusion of the minor role of hierarchy may prove to be true for some tasks but not for others. I suspect the importance of different components of the HRM may well vary by type of task.
For researchers interested in more efficient, more biologically and brain inspired models, the HRM is a welcome advance and offers exciting paths for others to follow!
 | A guest post by
|
The fact that it has only 27M parameters and can potentially compete with much larger models, shows inherent logic/intelligence. In my past experience, hierarchal models have higher cost and would look forward the overall ROI here.